Table of Contents
HOWTO: Set up and secure a local Spark-Core Cloud
It took quite a bit of tinkering and a couple of clarifying sessions on IRC (Thanks to lbt and aholler for their input and support), to deploy the local Spark-Cloud test setup and interpret/abstract the scattered docs into one whole system view model. But why go through all this hassle, when you can just comfortably use the “official” spark.io cloud service to develop & manage your cores instantly?
Well, the IoT (Internet of Things) is a hip buzzword these days and the Spark-Cores definitely can be categorized as the first generation of open, relatively cheap and hackable wireless IoT devices.
For all we know, it is at least save to assume, that we actually have no way of knowing how far this technology branch is going to develop and spread in a couple of years, just like the Internet itself 20 years ago. We should look at the privacy aspects before it's actually too late to do so. In the end, it boils down to this question:
Do we really want to give out our complete sensory data (sys/env/biometrics) over all time and possibly full remote control over all the actors, built into everything, at all time, at the place we like to call our home?
Some people may haven't yet realized that we've got plenty of open-source tools to store, analyze, link and visualize billions of data rows quickly and with much ease. Imagine what people with a multi-billion budget are able to employ. To give you a small scale example, how transparent anyone's little life and habits become, I've created a dashboard which doesn't show many metrics yet (more are in the process) but it's more than enough, if you learn how to interpret the graphs. The data you see there is mostly generated by two spark-cores which are deployed here. Big/Open-Data/Cloud technology is not the problem itself, it's our culture/society, which obviously isn't ready for it.
In the year 2014, in a post Olympic Games (Stuxnet) & Nitro Zeus, Snowden & Lavabit era, we have no other choice but to come out of our state of denial and simply accept the fact, that every commercial entity can be compromised through multiple legal, administrative, monetary, social/personal or technological levers. Access- and Cloud-Provider are no exception. As repeatedly shown, all of them can be tricked, coerced or forced to “assist” in one way or another. No matter what anyone promises, from this point on, they all have to be considered compromised.
The current software implementation (firmware- and server-side) has no concept of mesh/p2p or direct networking/communication. All Spark-Cores need a centralized spark-server for Control & Communication. Also, the Spark.connect() routine unfortunately has no timeout (yet?), the Core might hang indefinitely, which could be a big problem, even if your particular code doesn't require to connect to the cloud because after you call Spark.connect(), your loop will not be called again until the Core finishes connecting to the Cloud. This might happen if your WiFI or internet access is offline.
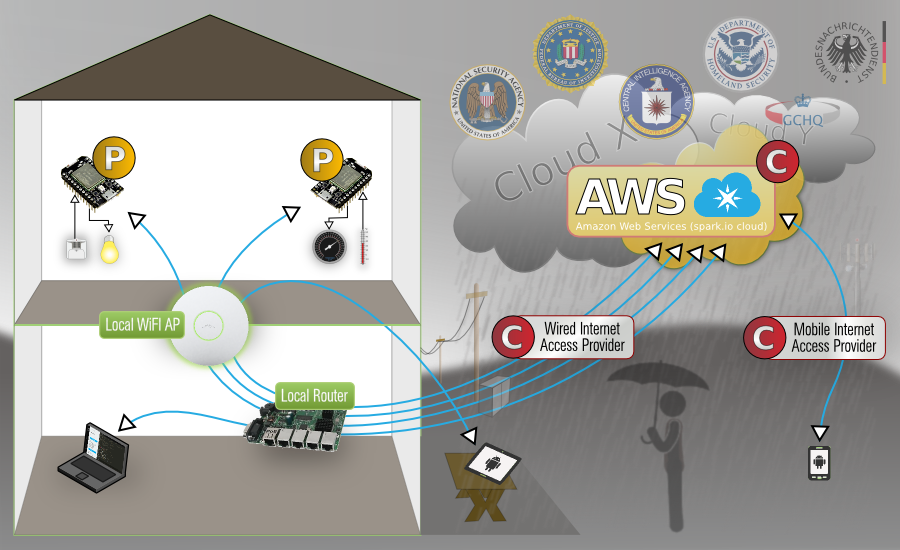
In this picture the blue lines represent the data flow of the Cores, the clients and the central server. All points marked with a red C show where the current implementation/infrastructure is to be considered compromised and the yellow P marks potential security risks (since the firmware isn't compiled locally), theoretically anything can be injected into the firmware, either in the AWS cloud or even in-stream. Tests showed that the API webservers don't offer perfect forward secrecy, the cores itself use only 128-CBC without DH support, which offers no forward secrecy at all. Not having reliable crypto and passing everything through compromised infrastructure can't be the way to go. Not to mention, the additional amount of required bandwidth this concept ultimately creates, when you consider the available IPv6 address space and a fair likelihood, that not so far off, there will be more IoT clients connected to the Internet, than there are humans.
Local Spark-Cloud Server Dataflow
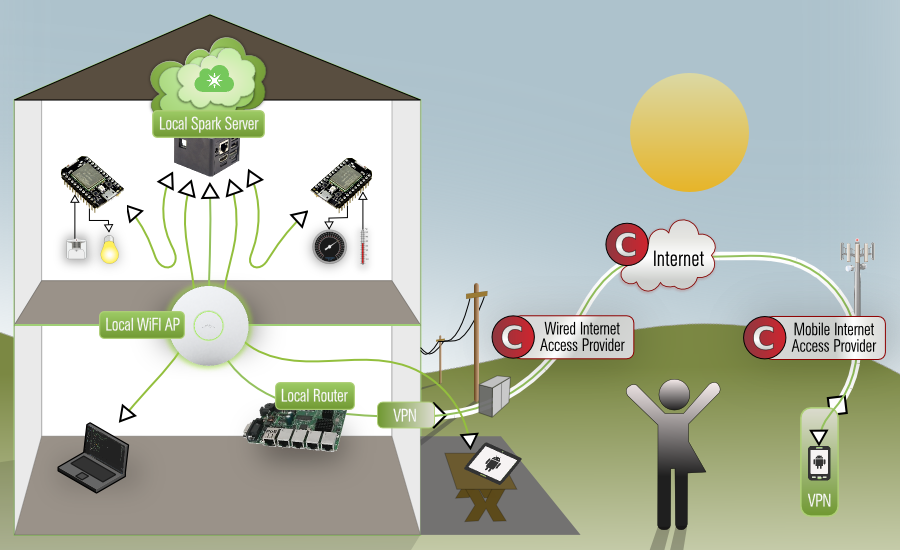
When you follow this howto and secure your network access with a strong VPN (AirVPN used here) you'll end up with something that looks like this image, where we effectively mitigate all these issues and take back control of our privacy & autonomy. At least we now can decide if and which data we want to share and publish.
Key Features/Aspect Comparison
| Remote Spark-Cloud (AWS) | Local Spark-Cloud Server | |
|---|---|---|
| Easy start with WebIDE | Yes | Manual setup required |
| Offline Development with Atom and git | No (Use WebIDE) | Yes |
| Number of exposable functions | 4 | unlimited1) |
| Number of exposable variables | 10 | unlimited2) |
| Local Cross-Compiler Toolchain needed | No | Yes |
| Cores still work when Internet is offline | No3) | Yes |
| Perfect Privacy/Forward Secrecy | No4) | Yes5) |
| Core Firmware can be trusted | Potentially Not | Yes |
| OTA Update capability | Yes (But potentially insecure) | Yes |
| Minimum Avg. Non-US Network Latency | >100ms | <10ms (LAN/WiFI) |
Installation
Dependencies
dfu-util
To claim, configure and flash our Cores locally we'll need dfu-util >= 0.7.0
$ emerge -av dfu-util
In this guide I've used the 9999 gentoo ebuild, which pulls and builds the current git master, on other distros your mileage may vary.
Node.js
$ emerge -av nodejs
Make sure the npm USE flag is set to get the node package manager as well
Cross Compiler Toolchain
At this time is wasn't possible yet to use a gentoo crossdev toolchain to compile the firmware since it seems to require newlib-nano instead of the plain newlib gentoo would like to merge. There wasn't enough time to hunt down this particular bug further so the official toolchain was used instead.
$ mkdir spark-core $ cd spark-core
$ wget https://launchpad.net/gcc-arm-embedded/4.8/4.8-2014-q2-update/+download/gcc-arm-none-eabi-4_8-2014q2-20140609-linux.tar.bz2 $ tar xvjpf gcc-arm-none-eabi-4_8-2014q2-20140609-linux.tar.bz2
Tell your system to pick it up automatically:
$ export PATH=$PATH:$HOME/src/spark-core/gcc-arm-none-eabi-4_8-2014q2/bin
Core/Firmware
$ git clone https://github.com/spark/core-firmware.git $ git clone https://github.com/spark/core-common-lib.git $ git clone https://github.com/spark/core-communication-lib.git
Make sure you checkout the three core repos into the same folder, otherwise it won't build.
Spark Server
$ git clone https://github.com/spark/spark-server.git
Spark CLI
$ npm install -g spark-cli (need either root or sudo)
Configuration & Usage
Local Spark cloud server
$ cd spark-server/js
$ npm install
$ node main.js
-------
No users exist, you should create some users!
-------
connect.multipart() will be removed in connect 3.0
visit https://github.com/senchalabs/connect/wiki/Connect-3.0 for alternatives
connect.limit() will be removed in connect 3.0
Starting server, listening on 8080
static class init!
core keys directory didn't exist, creating... /home/chrono/src/spark-core/spark-server/js/core_keys
Creating NEW server key
Loading server key from default_key.pem
set server key
server public key is:
-----BEGIN PUBLIC KEY-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA2UuRHTMfftLH/w814i9x
5H3dFElK4J4Zp3SkF3Ere3pS/DVBJUG1MAirv6jfGP3knmWORR9hWEdjqJNGwAms
SESv5Ztt6zxlB4vbmzkK914bj/d8UuBjEFczfOh5YX65lQUdKm5arxjGza9I8tN+
i+mdy/bNg3go9V1NflWNm0LQswwtBeVP0kdo/YOh8GJS7VZXyPIgDB/SrmgXfdvE
crAaE/0LiaI6/sOrMn7INirGJaHfkzSNs1yBZ0ZTci9HbFH0A/prwG5H5qmUVARa
5eQ2T/Zk8I+QuBzjaqTqNLn+rOmbTDWT0pQCdIHJMURcKRDE54ChZeAMw3Sft5jO
nQIDAQAB
-----END PUBLIC KEY-----
Your server IP address is: 192.168.1.100
server started { host: 'localhost', port: 5683 }
Spark-CLI Configuration
Spark-CLI usually wants to connect to the official Spark cloud, so we need to tell it where to connect instead. Since our spark-server told us it is listening on 192.168.1.100 we just say:
$ spark config local api-url http://192.168.1.100:8080 $ spark config local
This will create/update the spark-cli configuration found in ~/.spark/ reflecting our wish to use the local cloud instance running on 192.168.1.100 instead of the public one. At the point of writing these features are not yet documented but this commit worked here.
Prepare a new Spark-Core
Let's leave the server running in this shell and open another terminal to configure the core. Now it's also a good time to connect your Micro-USB cable to the Spark-Core.
Update factory firmware & CC3000 code
If this is a new Spark-Core, we want to run a special firmware program (deep-update), that will update the firmware running inside the CC3000 WiFi module. Put your Spark-Core in DFU-Mode by simultaneously pressing the MODE and RESET buttons, then releasing RESET while continuing to hold MODE for at least 3 seconds until the LED starts blinking (3-4Hz) yellow (red+green).
$ spark flash --usb deep_update_2014_06
FOUND DFU DEVICE 1d50:607f checking file /usr/lib64/node_modules/spark-cli/binaries/deep_update_2014_06.bin spawning dfu-util -d 1d50:607f -a 0 -i 0 -s 0x08005000:leave -D /usr/lib64/node_modules/spark-cli/binaries/deep_update_2014_06.bin dfu-util 0.7 [...] Filter on vendor = 0x1d50 product = 0x607f Opening DFU capable USB device... ID 1d50:607f Run-time device DFU version 011a Found DFU: [1d50:607f] devnum=0, cfg=1, intf=0, alt=0, name="@Internal Flash /0x08000000/20*001Ka,108*001Kg" Claiming USB DFU Interface... Setting Alternate Setting #0 ... Determining device status: state = dfuERROR, status = 10 dfuERROR, clearing status Determining device status: state = dfuIDLE, status = 0 dfuIDLE, continuing DFU mode device DFU version 011a Device returned transfer size 1024 No valid DFU suffix signature Warning: File has no DFU suffix DfuSe interface name: "Internal Flash " Downloading to address = 0x08005000, size = 93636 ............................................................................................ File downloaded successfully Transitioning to dfuMANIFEST state Error during download get_status Flashed!
Don't worry about the “Error during download get_status”, apparently this is “normal” and doesn't mean the flash process failed. When the LED is blinking (3-4Hz) green, put it into DFU-Mode again and flash a regular firmware like Tinker to get connected and developing again.
$ spark flash --usb tinker
ID your Core
Put your Spark-Core into Listening-Mode by pressing and holding the MODE button until the LED is blinking (2Hz) blue. Now run the following command to get your Core's ID:
$ spark identify
Your core id is: 1234567890abcdef
Note/copy this ID, you'll need it soon again.
Upload local Spark-Cloud's pub-key to Spark-Core
Now that we've got the Spark-CLI ready, we can supply our Spark-Core with the public key of our freshly deployed spark-server. This actually is a good practice against DNS hijacking or other man-in-the-middle type attacks because our Spark-Cores can now determine that they are communicating with our server and not someone else's. It would be good to have some of the more stack/sec oriented people looking deeper into the code.
$ cd spark-core/spark-server/js $ ls -al default*
-rw-r--r-- 1 chrono users 1679 Sep 25 11:27 default_key.pem -rw-r--r-- 1 chrono users 451 Sep 25 11:27 default_key.pub.pem
Put the Spark-Core into DFU mode again and then execute:
$ spark keys server default_key.pub.pem 192.168.1.100
Creating DER format file running openssl rsa -in default_key.pub.pem -pubin -pubout -outform DER -out default_key.pub.der checking file default_key.pub192_168_1_100.der spawning dfu-util -d 1d50:607f -a 1 -i 0 -s 0x00001000 -D default_key.pub192_168_1_100.der dfu-util 0.7 [...] Filter on vendor = 0x1d50 product = 0x607f Opening DFU capable USB device... ID 1d50:607f Run-time device DFU version 011a Found DFU: [1d50:607f] devnum=0, cfg=1, intf=0, alt=1, name="@SPI Flash : SST25x/0x00000000/512*04Kg" Claiming USB DFU Interface... Setting Alternate Setting #1 ... Determining device status: state = dfuERROR, status = 10 dfuERROR, clearing status Determining device status: state = dfuIDLE, status = 0 dfuIDLE, continuing DFU mode device DFU version 011a Device returned transfer size 1024 No valid DFU suffix signature Warning: File has no DFU suffix DfuSe interface name: "SPI Flash : SST25x" Downloading to address = 0x00001000, size = 1024 . File downloaded successfully Okay! New keys in place, your core will not restart.
Create new keys for your core
Put the Spark-Core into DFU mode again and then execute:
$ mkdir core_keys $ cd core_keys $ spark keys doctor 1234567890abcdef
FOUND DFU DEVICE 1d50:607f running openssl genrsa -out 1234567890abcdef_new.pem 1024 running openssl rsa -in 1234567890abcdef_new.pem -pubout -out 1234567890abcdef_new.pub.pem running openssl rsa -in 1234567890abcdef_new.pem -outform DER -out 1234567890abcdef_new.der New Key Created! FOUND DFU DEVICE 1d50:607f FOUND DFU DEVICE 1d50:607f running dfu-util -d 1d50:607f -a 1 -s 0x00002000:1024 -U pre_1234567890abcdef_new.der running openssl rsa -in pre_1234567890abcdef_new.der -inform DER -pubout -out pre_1234567890abcdef_new.pub.pem Saved! checking file 1234567890abcdef_new.der spawning dfu-util -d 1d50:607f -a 1 -i 0 -s 0x00002000:leave -D 1234567890abcdef_new.der dfu-util 0.7 Copyright 2005-2008 Weston Schmidt, Harald Welte and OpenMoko Inc. Copyright 2010-2012 Tormod Volden and Stefan Schmidt This program is Free Software and has ABSOLUTELY NO WARRANTY Please report bugs to dfu-util@lists.gnumonks.org Filter on vendor = 0x1d50 product = 0x607f Opening DFU capable USB device... ID 1d50:607f Run-time device DFU version 011a Found DFU: [1d50:607f] devnum=0, cfg=1, intf=0, alt=1, name="@SPI Flash : SST25x/0x00000000/512*04Kg" Claiming USB DFU Interface... Setting Alternate Setting #1 ... Determining device status: state = dfuUPLOAD-IDLE, status = 0 aborting previous incomplete transfer Determining device status: state = dfuIDLE, status = 0 dfuIDLE, continuing DFU mode device DFU version 011a Device returned transfer size 1024 No valid DFU suffix signature Warning: File has no DFU suffix DfuSe interface name: "SPI Flash : SST25x" Downloading to address = 0x00002000, size = 610 . File downloaded successfully Transitioning to dfuMANIFEST state Error during download get_status Saved! attempting to add a new public key for core 1234567890abcdef submitting public key succeeded! Okay! New keys in place, your core should restart.
Claim the Spark-Core
Press RESET on the core and/or hold the MODE button until the core goes back to listening mode (blinking blue). In order to create a new user and claim your first core we simply run:
$ spark setup
If you run this the first time, you'll have to create an
account in your local cloud first:
========================================
Setup your account
Could I please have an email address? myemail@domain.net
and a password? *******
Trying to login...
Login failed, Lets create a new account!
confirm password *******
creating user: myemail@domain.net
user creation succeeded!
Got an access token! 7yxc7yxc7yxc7yxc7yxc7yxc7yxc7yxc7yxc
Logged in! Saving access token: 7yxc7yxc7yxc7yxc7yxc7yxc7yxc7yxc7yxc
Using the setting "access_token" instead
Now that we have created a user and are logged in (got an access token)
we can claim our core:
----------------------
Finding your core id
Your core id is: 1234567890abcdef
========================================
Setup your wifi
SSID: mySSID
Security 0=unsecured, 1=WEP, 2=WPA, 3=WPA2: 3
Wifi Password: myWifiPSK
Attempting to configure wifi on /dev/ttyACM0
I said: w
Serial said: SSID:
I said: mySSID
Serial said: mySSID
Security 0=unsecured, 1=WEP, 2=WPA, 3=WPA2:
I said: 3
Serial said: 3
Password:
I said: myWifiPSK
Serial said: myWifiPSK
Thanks! Wait about 7 seconds while I save those credentials...
Awesome. Now we'll connect!
If you see a pulsing cyan light, your Spark Core
has connected to the Cloud and is ready to go!
If your LED flashes red or you encounter any other problems,
visit https://www.spark.io/support to debug.
Spark <3 you!
Done! Your core should now restart.
Please wait until your core is breathing cyan and then press ENTER
The Led should now slowly pulsate in cyan (blue+green) and your spark-server should show something in the console like:
Connection from: 192.168.1.123, connId: 1
on ready { coreID: '123456789abcdef',
ip: '192.168.1.123',
product_id: 0,
firmware_version: 10,
cache_key: '_0' }
Core online!
Check/List cores
$ spark list
Checking with the cloud...
Retrieving cores... (this might take a few seconds)
tinkertest (123456789abcdef) is online
Functions:
int digitalread(String args)
int digitalwrite(String args)
int analogread(String args)
int analogwrite(String args)
Compile firmware
Default Firmware
$ cd core-firmware/build
$ make clean all
Building core-common-lib make[1]: Nothing to be done for `all'. Building core-communication-lib make[1]: Nothing to be done for `all'. Building target: core-firmware.elf Invoking: ARM GCC C++ Linker mkdir -p ./ arm-none-eabi-g++ -g3 -gdwarf-2 -Os -mcpu=cortex-m3 -mthumb -I../inc -I../libraries/Serial2 -I../../core-common-lib/CMSIS/Include -I../../core-common-lib/CMSIS/Device/ST/STM32F10x/Include -I../../core-common-lib/STM32F10x_StdPeriph_Driver/inc -I../../core-common-lib/STM32_USB-FS-Device_Driver/inc -I../../core-common-lib/CC3000_Host_Driver -I../../core-common-lib/SPARK_Firmware_Driver/inc -I../../core-common-lib/SPARK_Services/inc -I../../core-communication-lib/lib/tropicssl/include -I../../core-communication-lib/src -I. -ffunction-sections -Wall -fmessage-length=0 -Werror=deprecated-declarations -MD -MP -MF core-firmware.elf.d -DUSE_STDPERIPH_DRIVER -DSTM32F10X_MD -DDFU_BUILD_ENABLE -DSPARK=1 -DRELEASE_BUILD ./obj/src/spark_wiring_random.o ./obj/src/spark_wiring_tcpserver.o ./obj/src/application.o ./obj/src/spark_wiring_i2c.o ./obj/src/spark_wiring_usartserial.o ./obj/src/spark_wiring_interrupts.o ./obj/src/spark_wiring_usbserial.o ./obj/src/spark_wiring_ipaddress.o ./obj/src/usb_endp.o ./obj/src/usb_prop.o ./obj/src/spark_wiring_stream.o ./obj/src/spark_wiring.o ./obj/src/spark_wiring_print.o ./obj/src/stm32_it.o ./obj/src/spark_wiring_string.o ./obj/src/main.o ./obj/src/spark_wiring_wifi.o ./obj/src/spark_wiring_eeprom.o ./obj/src/spark_wiring_tone.o ./obj/src/usb_desc.o ./obj/src/newlib_stubs.o ./obj/src/wifi_credentials_reader.o ./obj/src/spark_wiring_udp.o ./obj/src/spark_wiring_time.o ./obj/src/spark_utilities.o ./obj/src/spark_wiring_tcpclient.o ./obj/src/spark_wlan.o ./obj/src/usb_istr.o ./obj/src/spark_wiring_spi.o ./obj/src/spark_wiring_servo.o ./obj/src/startup/startup_stm32f10x_md.o --output core-firmware.elf -T../linker/linker_stm32f10x_md_dfu.ld -nostartfiles -Xlinker --gc-sections -L../../core-common-lib/build -lcore-common-lib -L../../core-communication-lib/build -lcore-communication-lib -Wl,-Map,core-firmware.map --specs=nano.specs -lc -lnosys -u _printf_float Invoking: ARM GNU Create Flash Image arm-none-eabi-objcopy -O binary core-firmware.elf core-firmware.bin Invoking: ARM GNU Create Flash Image arm-none-eabi-objcopy -O ihex core-firmware.elf core-firmware.hex Invoking: ARM GNU Print Size arm-none-eabi-size --format=berkeley core-firmware.elf text data bss dec hex filename 78672 1224 11864 91760 16670 core-firmware.elf
How do I create my own firmware?
Basically you can just go into core-firmware/applications and create a new folder with your project there. The Makefile looks for application.cpp in this folder. However, I found this a bit cumbersome and didn't want my code to be in the firmware's git repo, so I decided to put my spark projects into my main spark-core folder. Since I use atom as an editor I find it convenient to directly build the firmware from within the editor's UI without having to switch into a terminal window to build. This just calls a build shell script, which links the code into the core-firmware/applications folder, sets some env vars and calls the build with make APP=$projectname parameter. Automatic OTA update is also just a oneliner more in the same script. An example of this hackish construct is available under: https://github.com/apollo-ng/spark-lighter
OTA firmware update
It's possible to update the cores via Wifi, also called OTA (Over the Air) update. This is a really lovely feature, since we don't have to run around and deploy new firmware locally via USB but can just push new firmware to any ID we designate. I have this oneliner directly in my build script, so when I build directly in atom editor, it compiles the firmware and automatically pushes an OTA-Update to the designated core. If there were more core's with the same firmware, it should be easy enough to auto-update more than one.
$ spark flash 1234567890abcdef tinker
Including:
/usr/lib64/node_modules/spark-cli/binaries/spark_tinker.bin
attempting to flash firmware to your core 1234567890abcdef
flash core said {"id":"1234567890abcdef","status":"Update started"}
set_core_attributes { coreID: '1234567890abcdef',
userID: '1a2b3c4d5e6f7A8B9C0D' }
FlashCore { coreID: '1234567890abcdef',
userID: '1a2b3c4d5e6f7A8B9C0D+QQyn' }
flash core started! - sending api event { coreID: '1234567890abcdef' }
192.168.1.100 - - [Sun, 05 Oct 2014 09:34:18 GMT] "PUT /v1/devices/1234567890abcdef?access_token=060085e419be45ea4c4c1b7f09a443c2806a7fb3 HTTP/1.1" 200 68 "-" "-"
on response, no chunk, transfer done!
releasing flash ownership { coreID: '1234567890abcdef' }
flash core finished! - sending api event { coreID: '1234567890abcdef' }
Connection from: 192.168.1.123, connId: 185
on ready { coreID: '1234567890abcdef',
ip: '192.168.1.123',
product_id: 0,
firmware_version: 10,
cache_key: '_184' }
Core online!
Caveats
- Compiling through the local cloud is on the road map but doesn't work yet
Final Notes
Depending on your state of mind, you might perceive this as paranoid but I can guarantee you, this has nothing to do with paranoia in any way, neither should this be perceived as a rant against spark-core or Amazon Web Services for that matter. Amazon Web Services is just the cloud provider used by spark.io and therefore got mentioned because it is so. What applies here applies to any other cloud platform one could choose, in general. From a business standpoint of view the decision to put things into a AWS seems absolutely valid to me. Of course, it's a little more expensive when you crunch the numbers but in return you get the full orchestra of AWS products, which in my experience do a good job working together, route53, elb, multiple geolocations and the whole shabang. And you can react very quickly to changes in demand of requests. In a perfect world, I would just use it as it is, because the setup isn't bad when we consider bandwidth not a problem. But when government agencies run haywire and military/intelligence/media war- and fearmongering go completely out of hand, as it obviously has during the last 12 years and no one really does a thing about it, the only logical place left to seek change is in oneself. Do it yourself then :) I am happy, grateful and amazed that now everybody can get these devices to tinker, create and learn. Hopefully, some of these experiments and examples will help someone else to save some time, to get their brains wrapped around the concepts of this one more quickly.